 |
| HOME |
| Facebook Feed |
| BIO |
| PUBLICATIONS |
| arXiv Papers |
| G-Scholar Profile |
| SOFTWARE |
| CBLL |
| RESEARCH |
| TEACHING |
| WHAT's NEW |
| DjVu |
| LENET |
| MNIST OCR DATA |
| NORB DATASET |
| MUSIC |
| PHOTOS |
| HOBBIES |
| FUN STUFF |
| LINKS |
| CILVR |
| CDS |
| CS Dept |
| Courant |
| NYU |
| Websites that I maintain |
 |
 |
 |
 |

| Social Networks |
Facebook
Twitter: @ylecun
LinkedIn
| Biography |
bios of various lengths in English and en français
| Contact Information |
Yann LeCun,
VP and Chief AI Scientist, Facebook
Silver Professor of Computer Science, Data Science, Neural Science, and Electrical and Computer Engineering, New York University.
ACM Turing Award Laureate, (sounds like I'm bragging, but a condition of accepting the award is to write this next to you name)
Member, National Academy of Engineering
NYU Affiliations:
CILVR Lab
Computer Science Department, part of the Courant Institute of Mathematical Sciences,
Center for Data Science
Center for Neural Science
Department of Electrical and Computer Engineering,
Facebook Affiliations:
Facebook AI Research
Facebook AI
NYU coordinates:
Address: Room 516, 60 Fifth Avenue, New York, NY 10011, USA.
Email: yann [ a t ] cs.nyu.edu (I may not respond right away)
Phone: +1-212-998-3283 (I am very unlikely to respond or listen to voice mail in a timely manner)
Administrative aide: Hong Tam +1-212-998-3374 hongtam [ a t ] cs.nyu.edu
Facebook Coordinates:
Address: 770 Broadway, New York, NY 10003
Email: yann [ a t ] fb.com (I may not respond right away)
Executive assistant: Daniella Kalfa: dkalfa [ a t ] fb.com
FOR INVITATIONS TO SPEAK: please send email to lecuninvites[at]gmail.com
(I really can't handle invitations sent to other email addresses)
IF YOU REALLY NEED ME TO DO SOMETHING FOR YOU: (e.g. a review, a letter...) please send email to Daniella Kalfa dkalfa[at]fb.com
| Publications, Talks, Courses, Videos |
Publications:
Google Scholar
Papers on OpenReview.net
Preprints on ArXiv
Out of date list of publications with PDFs and DjVu
Talks / Slide Decks:
Slides of (most of my) talks
Deep Learning Course:
Deep Learning course at NYU:
Complete course on Deep Learning, with all the material available on line including lecture and practicum videos, slide decks, homeworks, Jupyter notebooks, and transcripts in several languages.
Videos: Playlists on YouTube:
- Talks by Yann LeCun
- Lectures Series by Yann LeCun
- Debates and Panels with Yann LeCun
- Interviews of Yann LeCun
- Demos by Yann LeCun
- Six short videos to explain AI, Machine Learning, Deep Learning and Convolutional Nets
Main Research Interests:
AI, Machine Learning, Computer Vision,
Robotics, and Computational Neuroscience. I am also interested
Physics of Computation, and many applications of machine learning.
[stuff below this line is badly out of date]
| Quick Links |
- Center for Data Science, and the NYU Data Science Portal.
- Computational and Biological Learning Lab, my research group at the Courant Institute, NYU.
- CILVR Lab: Computational Intelligence, Vision Robotics Lab: a lab with many NYU faculty, students and postdocs working on AI, ML and applications thereof such as computer Vision, NLP, robotics, and healthcare.
- Research: descriptions of my projects and contributions, past and present.
- Publications: (almost) all of my publications, available in PDF and DjVu formats.
- Google Scholar Profile: all my publications with number of citations, harvested by Google.
- Preprints on ArXiv.org: where you will find our latest results, before they may receive a stamp of approval.
| Computational and Biological Learning Lab |
| My lab at the Courant Institute of New york University is called the Computational and Biological Learning Lab. |  |
See research projects descriptions, lab member pages, events, demos, datasets...
We are working on a class of learning systems called Energy-Based Models, and Deep Belief Networks. We are also working on convolutional nets for visual recognition , and a type of graphical models known as factor graphs.
We have projects in computer vision, object detection, object recognition, mobile robotics, bio-informatics, biological image analysis, medical signal processing, signal processing, and financial prediction,....

| Teaching |
Jump to my course page at NYU, and see course descriptions, slides, course material...
| Talks and Tutorials |
See, watch and hear talks and tutorial.
| Pamphlets and opinions |
Proposal for a new publishing model in Computer Science
Many computer Science researchers are complaining that our emphasis on highly selective conference publications, and our double-blind reviewing system stifles innovation and slow the rate of progress of Science and technology.
This pamphlet proposes a new publishing model based on an open repository and open (but anonymous) reviews which creates a "market" between papers and reviewing entities.
| Deep Learning |
Animals and humans can learn to see, perceive, act, and communicate with an efficiency that no Machine Learning method can approach. The brains of humans and animals are "deep", in the sense that each action is the result of a long chain of synaptic communications (many layers of processing). We are currently researching efficient learning algorithms for such "deep architectures". We are currently concentrating on unsupervised learning algorithms that can be used to produce deep hierarchies of features for visual recognition. We surmise that understanding deep learning will not only enable us to build more intelligent machines, but will also help us understand human intelligence and the mechanisms of human learning.
| Relational Regression |
We are developing a new type of relational graphical models that can be applied to "structured regression problem". A prime example of structured regression problem is the prediction of house prices. The price of a house depends not only on the characteristics of the house, but also of the prices of similar houses in the neighborhood, or perhaps on hidden features of the neighborhood that influence them. Our relational regression model infers a hidden "desirability sruface" from which house prices are predicted.
| Mobile Robotics |
|
The purpose of the LAGR project,
funded by the US government, is to design vision and learning algorithms
to allow mobile robots to navigate in complex outdoors
environment solely from camera input.
My Lab, collaboration with Net-Scale Technologies is one of 8 participants in the program (Applied Perception Inc., Georgia Tech, JPL, NIST, NYU/Net-Scale, SRI, U. Penn, Stanford). Each LAGR team received identical copies of the LAGR robot, built be the CMU/NREC.
|

|
|
The government periodically runs competitions between the teams.
The software from each team is loaded and run by the goverment team
on their robot.
The robot is given the GPS coordinates of a goal to which it must drive as fast as possible. The terrain is unknown in advance. The robot is run three times through the test course. The software can use the knowledge acquired during the early runs to improve the performance on the latter runs.
|

|
CLICK HERE FOR MORE INFORMATION, VIDEOS, PICTURES >>>>>.
Prior to the LAGR project, we worked on the DAVE project, an attempt to train a small mobile robot to drive autonomously in off-road environments by looking over the shoulder of a human operator.
CLICK HERE FOR INFORMATION ON THE DAVE PROJECT >>>>>.
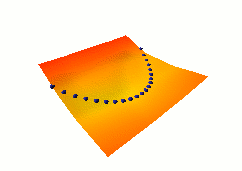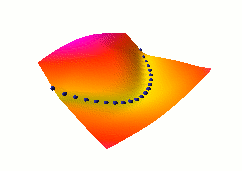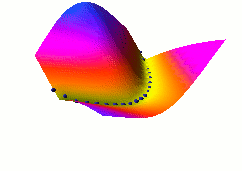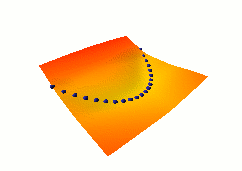
| Energy-Based Models |
|
Energy-Based Models (EBMs) capture dependencies between variables by
associating a scalar energy to each configuration of the
variables. Inference consists in clamping the value of observed
variables and finding configurations of the remaining variables that
minimize the energy. Learning consists in finding an energy
function in which observed configurations of the variables are given
lower energies than unobserved ones. The EBM approach provides a
common theoretical framework for many learning models, including
traditional discriminative and generative approaches, as well as
graph-transformer networks, conditional random fields, maximum margin
Markov networks, and several manifold learning methods.
Probabilistic models must be properly normalized, which sometimes requires evaluating intractable integrals over the space of all possible variable configurations. Since EBMs have no requirement for proper normalization, this problem is naturally circumvented. EBMs can be viewed as a form of non-probabilistic factor graphs, and they provide considerably more flexibility in the design of architectures and training criteria than probabilistic approaches. |
|
CLICK HERE FOR MORE INFORMATION, PICTURES, PAPERS >>>>>.
| Invariant Object Recognition |
 |
 |
|
The recognition of generic object categories with invariance to pose,
lighting, diverse backgrounds, and the presence of clutter is one of
the major challenges of Computer Vision.
I am developing learning systems that can recognize generic object purely from their shape, independently of pose and lighting. See The NORB dataset for generic object recognition is available for download. |

|
CLICK HERE FOR MORE INFORMATION, PICTURES, PAPERS >>>>>.
| Lush: A Programming Language for Research |
Lush combines three languages in one: a very simple to use, loosely-typed interpreted language, a strongly-typed compiled language with the same syntax, and the C language, which can be freely mixed with the other languages within a single source file, and even within a single function.
![]() Lush has a library of over 14,000 functions and classes,
some of which are simple interfaces to popular libraries:
vector/matrix/tensor algebra, linear algebra (LAPACK, BLAS),
numerical function (GSL), 2D and 3D graphics (X, SDL, OpenGL,
OpenRM, PostScipt), image processing, computer vision (OpenCV),
machine learning (gblearning, Torch), regular expressions,
audio processing (ALSA), and video grabbing (Video4linux).
Lush has a library of over 14,000 functions and classes,
some of which are simple interfaces to popular libraries:
vector/matrix/tensor algebra, linear algebra (LAPACK, BLAS),
numerical function (GSL), 2D and 3D graphics (X, SDL, OpenGL,
OpenRM, PostScipt), image processing, computer vision (OpenCV),
machine learning (gblearning, Torch), regular expressions,
audio processing (ALSA), and video grabbing (Video4linux).
If you do research and development in signal processing, image processing, machine learning, computer vision, bio-informatics, data mining, statistics, or artificial intelligence, and feel limited by Matlab and other existing tools, Lush is for you. If you want a simple environment to experiment with graphics, video, and sound, Lush is for you. Lush is Free Software (GPL) and runs under GNU/Linux, Solaris, and Irix.
| DjVu: The Document Format for Digital Libraries |
![]()
 My main research topic until I left AT&T was the
DjVu project.
DjVu is a document format, a set of compression methods and a software
platform for distributing scanned and digitally produced documents on the Web.
DjVu image files of scanned documents are typically 3-8 times
smaller than PDF or TIFF-groupIV for bitonal and 5-10 times
smaller than PDF or JPEG for color (at 300 DPI). DjVu versions
of digitally produced documents are more compact and render
much faster than the PDF or PostScript versions.
My main research topic until I left AT&T was the
DjVu project.
DjVu is a document format, a set of compression methods and a software
platform for distributing scanned and digitally produced documents on the Web.
DjVu image files of scanned documents are typically 3-8 times
smaller than PDF or TIFF-groupIV for bitonal and 5-10 times
smaller than PDF or JPEG for color (at 300 DPI). DjVu versions
of digitally produced documents are more compact and render
much faster than the PDF or PostScript versions.
Hundreds of websites around the world are using DjVu for Web-based and CDROM-based document repositories and digital libraries.
- Yann's DjVu page: a description of DjVu, and a set of useful links.
- Technical talk on DjVu: watch a streaming video of Yann's Distinguished Lecture at the University of Illinois at Urbana-Champaign, October 22 2001. (100K Windows Streaming Media). (56K Windows Streaming Media),
- DjVuZone.org: samples, demos, technical information, papers, and tutorials on DjVu.... DjVuZone hosts several digital libraries, including NIPS Online.
- DjVuLibre for Unix: free/open-source browser plug-ins, viewers, utilites, and libraries for Unix.
- Commercial DjVu Software: free plug-ins for Windows and Mac, free and commercial applications for Windows and some Unix platforms (hosted at LizardTech, the company that distributes and supports DjVu under license from AT&T).
- Any2DjVu and Bib2Web: Upload your documents and get them converted to DjVu. Bib2Web automates the creation of publication pages for researchers.
| Learning and Visual Perception |
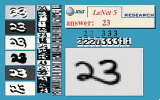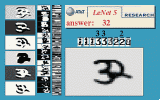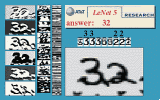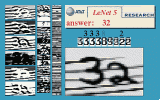 My main research interest is machine learning, particularly how it applies
to perception, and more particularly to visual perception.
My main research interest is machine learning, particularly how it applies
to perception, and more particularly to visual perception.
I am currently working on two architectures for gradient-based perceptual learning: graph transformer networks and convolutional networks.
Convolutional Nets are a special kind of neural net architecture designed to recognize images directly from pixel data. Convolutional Nets can be trained to detect, segment and recognize objects with excellent robustness to noise, and variations of position, scale, angle, and shape.
Have a look at the animated demonstrations of LeNet-5, a Convolutional Nets trained to recognize handwritten digit strings.
Convolutional nets and graph transformer networks are embedded in several high speed scanners used by banks to read checks. A system I helped develop reads an estimated 10 percent of all the checks written in the US.
Check out this page, and/or read this paper to learn more about Convolutional Nets and graph transformer networks.
| MNIST Handwritten Digit Database |
The MNIST database contains 60,000 training samples and 10,000 test samples of size-normalized handwritten digits. This database was derived from the original NIST databases.
MNIST is widely used by researchers as a benchmark for testing pattern recognition methods, and by students for class projects in pattern recognition, machine learning, and statistics.
| Music and Hobbies |
I have several interests beside my family (my wife and three sons) and my research:
- Playing Music: particularly Jazz, Renaissance and Baroque music. A few MP3 and MIDI files of Renaissance music are available here.
- Building and flying miniature flying contraptions:
preferably battery powered, radio controled, and unconventional in their design.

- Building robots: particularly Lego robots (before the days of the Lego Mindstorms)
- Hacking various computing equipment: I have owned 5 computers between 1978 and 1992: SYM-1, OSI C2-4P, Commodore 64, Amiga 1000, Amiga 4000. then I lost interest in personal computing when the only thing you could get was a boring Wintel box. Then, Linux appeared and I came back to life.....
- Sailing: I own two sport catamarans, a Nacra 5.8 and a Prindle 19. I also sail and race larger boats with friends.
- Graphic Design: I designed the DjVu logo and much of the AT&T DjVu web site.
- Reading European comics. Comics in certain European countries (France, Belgium, Italy, Spain) are considered a true art form ("le 8-ieme art"), and not just a business with products targeted at teenagers like on this side of the pond. Although I don't have a shred of evidence to support it, I claim to have the largest private collection of French-language comics in the Eastern US.
- making bad puns in French, but I don't have much of an audience this side of the pond.
- Sipping wine, particularly red, particularly French, particularly Bordeaux, particularly Saint-Julien.
| Bib2Web: Automatic Creation of Publication Pages |
| Photos Galleries |
- Photos taken at various conferences, workshops, trade shows and other professional events. Includes pictures from CVPR, NIPS, Learning@Snowbird, ICDAR, CIFED, etc.
- A photo and movie gallery of various radio-controled airplanes, other miniature flying objects, lego robots, and other techno toys. Check out also my model airplane page.
- Miscellaneous artsy and nature picture, including garden-variety wild animals, landscapes, etc.
- Vintage airplanes at the national air and space museum in Le Bourget, near Paris.
| Fun Stuff |
- No, Yann is NOT Philippe Kahn's evil brother
- Your Name can't possibly be pronounced that way: or how a Nobel prize winner tried to tell me how to pronounce my own name.
- Who is Tex Avery anyway?
- Steep Learning Curves and other erroneous metaphores
- Vladimir Vapnik meets the video game sub-culture
- Cheap Philosophy (42 cents)
- A Mathematical Theory of Empty Disclaimers
- The Axis of Rivals
| Previous Life |
My former group at AT&T (the Image Processing Research Department) and its ancestor (Larry Jackel's Adaptive Systems Research Department) made numerous contributions to Machine Learning, Image Compression, Pattern Recognition, Synthetic Persons (talking heads), and Neural-Net Hardware. Specific contributions not mentioned elsewhere on this site include the ever so popular Support Vector Machine, the PlayMail and Virt2Elle synthetic talking heads, the Net32K and ANNA neural net chips, and many others. Visit my former group's home page for more details.
| Links |
Links to interesting places on the web, friends' home pages, etc .
